cookiecount– Load a page and show the cookies it sets
$ ./cookiecount https://example.com
0 cookies received.
ps1_anon.bash – anonymize bash prompt, for screenshots and pastes
# Anonymize bash prompt for screenshots and pastes
# Source from or add to ~/.bashrc
function ps1_anon (){
if [[ -v SAVED_PS1 ]]
then
PS1="${SAVED_PS1}"
unset SAVED_PS1
else
SAVED_PS1="${PS1}"
PS1='\$ '
fi
}
Urlwatch for a new package version in an APT repository
After a long wait, I was finally able to find another use for my awful Perl one-liner from 2019 that pivots a Debian Packages.gz into a space-separated table!
“Haltet die Fresse! Glotzt mehr TV!”, das wählte ich im Sommer 2007 als Überschrift, irgendwie ganz und gar nicht im Verfolgungswahn, unter dem Eindruck des damals bereits nicht mehr ganz so frischen Landgerichts Hamburg, der noch etwas neueren Impressumpflicht, TKÜV, Mediendienstestaatsvertrag und Teledienstgesetz, und dem damals noch richtig neuen Hackerparagraphen.
Danach war zwei Jahre Funkstille, aber irgendwann ab 2009 mussten die Blogposts dann doch aus mir raus, und ich veröffentlichte über die Jahre noch eine Handvoll Artikel quasi-pseudo-überhauptnicht-anonym unter binblog.info, einem auf WordPress gehosteten Blog.
Nun ist es auf perverse Weise noch viel schlimmer gekommen, als ich es in meiner Paranoia damals erwartete. Hass und kriminelle Beschimpfungen regieren die leichter zugänglichen Teile des Social Web, und bis auf allerschwerste Fälle wird das alles mit einem Schulterzucken hingenommen. Ruf doch die Polizei! Oder, noch schlimmer, das Ordnungsamt, weil auf einer deutschen Domain das Impressum fehlt! Ha! Schieß doch!
Ein richtiger Nerd lässt keine Domainregistrierung verfallen, das Haus verliert nichts, und hier ist nun also der Re-Launch auf der alten Domain von 2003. Datenschutzverträglich selbst gehostet, ohne Analysetools und Werbeeinblendungen des kommerziellen WordPress-Service. Fast 20 Jahre Content in 1200 auf Privat geschalteten Posts stecken in der Datenbank. Die “temporäre” Domain, binblog.info, wird in Kürze hier hin migriert. Ausgewählte Artikel, insbesondere aus der OpenSSH-Ecke, die zahlreich extern verlinkt sind, werde ich Zug um Zug wieder freischalten.
Der erste neue Post hier wird unter dem Motto “Too good to” stehen, für Fundstücke aus der täglichen Arbeit, die bei Github oder Twitter nur hoffnungslos untergehen würden.
Der Plan ist, ab dem Relaunch die gesamte Kommentarfunktion über ActivityPub abzuwickeln. Viel Spaß beim Experimentieren.
Sollte binblog.de mit diesem Post bei jemandem nach 15 Jahren im RSS-Reader wieder auftauchen, vielen Dank für deine Hartnäckigkeit, du hast mir die ganze Zeit aufs Übelste gefehlt!
Da ich mit meinen 48 Jahren seit kurzem Hörgeräte trage und immer wieder die selben Fragen und Geschichten höre, will ich mal aufschreiben, wie das so gelaufen ist.
Im Jahr 2004 operierte ich im Alter von 32 Jahren am Rand des Hörsturz herum und wurde vom notfallmäßig aufgesuchten HNO-Arzt gefragt, ob ich denn wisse, dass ich schwerhörig sei. Ich habe mir das nicht weiter zu Herzen genommen, sondern mit einem Schulterzucken abgetan aber ab da zumindest peinlichst darauf geachtet, bei jeglichen lauten Tätigkeiten, Konzertbesuchen u.ä., Gehörschutz zu tragen.
Irgendwann Mitte der 2010er Jahre wurde ich erneut von einem HNO-Arzt darauf angesprochen, bis der selbe Arzt mich im Herbst 2019 schließlich klar aufforderte, mal darüber nachzudenken, mir Hörgeräte anpassen zu lassen. Der Hörtest war in den hohen Tönen extrem durchwachsen und ein Test des Sprachverständnis wirklich miserabel ausgefallen. “WURST”, “DURST”, “ZANK”, “DANK”, “ZOPF”, “TOPF”, wer kann solche sprachlichen Feinheiten schon genau unterscheiden?
OMG erstmal googeln
Wer plötzlich mit diesem Hörgerätegedöns konfrontiert ist, will natürlich auf jeden Fall zunächst einmal und überhaupt unbedingt ein Gerät, das unsichtbar im Gehörgang verschwindet. Bloß kein so ein Ding hinterm Ohr. Nach etwas Recherche bleibt einem aber nichts anderes, als diese einfachen Umstände zu akzeptieren:
Wer Bluetooth will, muss aus dem Schädel draußen bleiben, um Funkempfang zu haben.
Niemand will sich einen Lithium-Ionen-Akku tief in den Gehörgang schieben. Es gibt keine Akku-Geräte für ins Ohr.
An dieser Stelle darf dennoch bereits gespoilert werden, dass Akku-Geräte auch hinterm Ohr äußerst unüblich sind. Gängig sind Geräte für die Batteriegrößen “Typ 10” und “Typ 312”. Typ 10 ist eine winzige Batterie mit 6mm Durchmesser und der Standard für Geräte im Gehörgang. Typ 312 ist mit 8mm Durchmesser immer noch ziemlich klein und, so wie ich das sehe, der gängigste Standard für Geräte hinterm Ohr.
Da ich bereits Erfahrung mit per Otoplastik angepassten Kopfhörern hatte, die im Gehörgang gern mal nervig, juckend und schwitzig werden, habe ich mich sehr früh gegen ein In-Channel-Gerät entschieden.
Was die Google-Ergebnisse angeht, gibt es im Internet kaum Informationen über Hörgeräte, bei denen es sich nicht um offizielle Verlautbarungen der Hersteller handelt. So gut wie alle jüngeren Hörgeräteträger im Netz sind von Geburt an schwerhörig und haben in dieser Lage wohl nochmal ganz eigene Filterblasen, innerhalb derer der Austausch über die Hardware stattfindet, wenn überhaupt.
Let’s do this
Im Oktober 2019 ging es also los und ich machte mich mit einer Verordnung vom Ohrenarzt auf den Weg zum Akustiker.
Der Siemens-Ableger Signia-Hörgeräte verkauft sich im Web ziemlich hochglänzend als der Marktführer schlechthin, und so startete auch der Akustiker erstmal mit dem Test des Signia Pure 312.
Signia Pure 312
Der Einstieg in die Benutzung dieser Geräte gestaltete sich dann allerdings deutlich weniger angenehm, als erwartet. Wo ich eben noch gelesen hatte, dass Apple iOS die beste Hörgeräteunterstützung bietet, lieferten sich plötzlich das iPhone und das iPad erbitterte Schlachten um die Lautstärkeregelung der Hörgeräte. Die Übergabe der Soundwiedergabe zwischen iPad und iPhone funktionierte bisweilen überhaupt nicht und beim Telefonieren wurden die eingebauten Mikrofone der Hörgeräte nicht benutzt, sondern ich musste das iPhone wie die sprichwörtliche Scheibe Knäckebrot vor den Mund halten.
Begleitet wurde das ganze von wiederkehrenden Störgeräuschen (“Zing!”), die ich auf Haare am Mikrofon zurückführte. Auf der Heimreise vom 36. Chaos Communication Congress kamen dann analog klingende Störgeräusche dazu, die sich anhörten, wie wenn an einem FM-Funkgerät die Rauschsperre kurz aufgeht. Was für ein digitales Gerät schon ziemlich bemerkenswert ist.
Mit meinem beträchtlichen Waschzettel an Macken diagnostizierten Akustiker und Hersteller einen Hardwaredefekt und die Pure 312 wurden durch andere Geräte des selben Modells ersetzt. Diese hatten leider die exakt selben Macken, waren dazu noch extrem empfänglich für Rückkopplungen und hatten extremst kurze und unsymmetrische (links noch einmal 50% kürzer als rechts) Batterielaufzeiten. Nach zwei weiteren Wochen wechselten wir dann auf ein anderes Modell von einem anderen Hersteller.
Sind wir bald da?
Nach der Pleite mit Signia ging es nun also mit einem OPN S 2 von Oticon weiter.
Oticon hat eine vollkommen unterschiedliche Plattform, die anders als Signia nicht nur keine Steuerung per Ultraschall mehr erlaubt, sondern auch Taschensender ausschließlich per Bluetooth Low Energy anbindet, dafür aber erstaunlicherweise nicht kabellos durch den Akustiker konfigurierbar ist. Als Träger wird man zur Anpassung mit einem wirklich beträchtlichen Kabelbaum behangen und der Akustiker muss dabei mit den vielleicht filigransten Adaptern hantieren, die ich je gesehen habe.
Leider zeigten sich sofort, noch im Studio des Akustikers, die selben Probleme mit der Bluetooth-Kommunikation. Im Gegensatz zu Signia gab es hier allerdings ein Telefongespräch mit dem Hersteller, bei dem folgendes rauskam:
Wenn man zwischen iPhone und iPad wechseln will, schaltet man besser beim jeweils ungenutzten Gerät Bluetooth aus.
Bluetooth Low Energy gibt die Nutzung der in den Hörgeräten verbauten Mikrofone zum Telefonieren nicht her, sondern da muss nochmal ein Stück Hardware zum anclipsen ran (bei Oticon: ConnectClip, bei Signia: Streamline Mic, jeweils ca. 200 Euro), das per Bluetooth mit dem Handy gekoppelt wird und das Mikrofon beinhaltet.
Das war jetzt nicht wahnsinnig begeisternd, aber zumindest klar kommuniziert.
Seit dem Umstieg auf Oticon habe ich keinerlei Störgeräusche mehr im Ohr. Es waren NICHT die Haare! Die Oticons in die Rückkopplung zu treiben, ist nahezu unmöglich, während ich bei Signia nur mit der Hand in die Nähe des Ohrs kommen musste. Zusammen mit der ganz gut gelungenen akustischen Anpassung der Oticon-Geräte werde ich den ganzen Tag kein einziges mal daran erinnert, dass ich Hörgeräte trage.
Stromversorgung
Oticon OPN S2
Wie schon gesagt, sind Akkugeräte unüblich. Sie fallen vor allem durch ihre kurze Laufzeit auf. Die Hersteller werben mit “Leistung für einen ganzen Tag” und selbst Signia verspricht für das Flaggschiff Styletto X in Verbindung mit dem Lade-Etui, also einer Hosentaschenbox mit Akku, wie man sie von den Apple Airpods kennt, nur 4 Tage Unabhängigkeit von der Stromversorgung.
Eine Zink-Luft-Batterie vom Typ 312 hält dagegen 6 Tage, in extrem ruhiger Umgebung auch mal 7 Tage, so dass man mit einem handelsüblichen Sixpack Batterien zum Preis von 2 Euro nicht nur für einen halben Monat unabhängig ist, sondern den international gängigen Batterietyp auch in der hinterletzten Ecke der Welt, wie etwa in der Apotheke oder im Baumarkt, nachkaufen kann.
Da Zink-Luft-Batterien bei Amazon in den Rezensionen massenhaft als “Fälschungen” oder “minderwertige Qualität” in der Luft zerrissen werden, sei an dieser Stelle noch einmal gesagt, dass jede Batterie nach dem Abpulen des Siegels mindestens eine Minute lang atmen muss, bevor man sie einsetzt. In den Batterien sind Luftlöcher, durch diese muss Sauerstoff reinkommen, und erst dann fangen die Dinger an, Spannung abzugeben. Ich habe erst um die 50 Batterien durch, aber bei denen war kein einziger Ausfall dabei.
Kopfhörer, Freisprechen etc.
Mit der so stark beworbenen Bluetooth-Funktionalität gibt es ja nun gewisse Probleme. Da meine Hörgeräte im Gehörgang mit “offenen” Gummischirmchen sitzen, können sie beim Musikhören keinen Bass wiedergeben, so dass ich sie allenfalls mal benutze, um am Handy ein Youtube-Video anzusehen. Steckt man das Handy mit dem Mikrofon nach oben in die Hemdtasche, kann man behelfsweise ganz ordentlich telefonieren.
Da die Oticon-Geräte sehr resistent gegen Rückkopplungen sind, kann man ohrumschließende Kopfhörer schnell drüberziehen, ohne mit Problemen rechnen zu müssen. Kopfhörer mit Active Noise Canceling funktionieren hervorragend, allerdings sind meine Hörgeräte mit ihrer Verstärkung hoher Töne nicht gerade hilfreich, wenn es um die hohen Töne geht, die ANC-Kopfhörer typischerweise nicht gut unterdrücken können.
Ich telefoniere weiterhin hauptsächlich mit meinen Jabra Evolve 75. Auch wenn diese leider ohraufliegend sind, ist die Sprachqualität beim Gegenüber einfach zu überragend, um irgendwelche Experimente zu unternehmen. Die Hörgeräte haben aber natürlich bei ohraufliegenden Kopfhörern absolut freie Bahn, um Außengeräusche ins Ohr zu pumpen. Nachdem ich endlos lange am Handy herumregeln musste, habe ich mir nun die Taste an den Hörgeräten mit der Mute-Funktion belegen lassen, so dass ich sie beim Telefonieren mit einem Handgriff einfach stummschalten kann.
Auf die Anschaffung des ConnectClip werde ich wohl verzichten, da ich mir davon keinen Nutzen verspreche.
Zwischenzeitlich bin ich auch Besitzer des oben bereits erwähnten ConnectClip, der genau wie beworben funktioniert.
Kosten
Es ist wahr, einfach alles. Die dunkle Seite, es gibt sie.
Ein solcher Satz Hörgeräte kostet 4000 Euro, und das ist noch nicht die oberste Preisklasse. Aus nichttrivialen Gründen habe ich beim Akustiker einen ausgesprochen hohen Rabatt auf den Eigenanteil bekommen, so dass ich nach Schnickschnack, Rezeptgebühr, Abschluss einer Versicherung und Rundungsdifferenz mit einem Kreditkartenbeleg von 1600 Euro aus dem Laden raus bin. Die angenommene Lebensdauer beträgt 6 Jahre; erst danach zahlt die Krankenkasse wieder ihre ca. 1500 Euro zu.
Ich habe das teure Gerät genommen, weil ich es kann und es mich technisch interessiert hat, aber wer sich zu einer solchen Ausgabe nicht in der Lage sieht, sollte auf jeden Fall Abstriche beim ohnehin mangelhaften Bluetoothzirkus machen. Auch bei den teuer vermarkteten Signalverarbeitungs-Features (etwa “Own Voice Processing” bei Signia) ist nicht alles Gold, was glänzt, und exzellente Ergebnisse wohl nur mit noch mehr Sitzungen beim Akustiker erreichbar. Die App und die ganze Smartphone-Fernsteuerung habe ich ebenfalls zur Seite gelegt, seit die Tasten an den endgültigen Geräten nach meinen Wünschen belegt sind.
Fazit
Bis die Geräte vernünftig angepasst waren, musste ich mich wirklich verflixt oft auf den Weg zum Akustiker machen. Ich kann mir gut vorstellen, dass manche Leute da irgendwann die Nerven verlieren, Ja und Amen sagen, und schließlich auf Geräten sitzen, die sie nicht tragen wollen.
Wieviel Kraft es das Gehirn gekostet haben muss, ständig zwischen den Zeilen zu interpolieren, was der Gesprächspartner wohl wirklich gesagt hat, merke ich erst jetzt deutlich. Diese Routine ist weg und wenn ich die Geräte heute ablege oder stummschalte, höre ich einfach nur noch unglaubliches Genuschel und frage mich, wie ich jahrelang so leben konnte. Im Garten höre ich wieder die Vögel singen und die Insekten summen. Ich kann ins Café zu meinem Stammtisch gehen, ohne dass ich irgendwann mental auf Durchzug schalten muss. Ich konnte mit den gerade so erstangepassten Signia-Geräten meine Frau zur Weihnachtsfeier ihrer Firma begleiten, ohne wie ein begriffsstutziger Zausel dabei zu sitzen.
Das klingt alles wie ein unglaubliches Klischee aus der Hörgerätereklame, ist aber wirklich genau so gelaufen.
Frage: “Hilft ein Hörgerät auch gegen Tinnitus-Geräusche?”
Ja. Ich höre zwei sehr hohe klirrende Töne um 8 und 10 kHz, die mich zwar noch nie am Einschlafen gehindert haben, aber tagsüber ganz schön zur Belastung werden können. Ich habe vor einiger Zeit mit Tinnitus-Playlisten auf Spotify experimentiert und diese bereits als Entlastung empfunden. Meine Hörgeräte haben einen aktivierbaren Tinnitus-Noiser, um ein relativ hochfrequentes Rauschen einzuspielen. Das kann in stressigen Situationen auf diskrete Weise als Entlastung dienen. Wichtiger ist in den meisten Situationen, dass der Tinnitus durch die Verstärkung der hohen Töne keine Sprachlaute mehr überdeckt. Dadurch kann er sich nicht mehr so einfach in den Vordergrund spielen.
While clicking around on time.is, which has a nice Esperanto translation that you may want to check out, I kept running into large-ish time offsets of at least several tenths of a second on a Windows 10 machine.
As a Linux guy, my first instinct was to replace the interval-based synchronization option in Windows with an NTP daemon, and so I found Meinberg’s ntpd distribution for Windows. While this ntpd would start flawlessly, over the course of every day it ran into some impossible to debug condition where NTP time reached a significant offset from the system clock again and unlike at startup, the daemon wouldn’t adjust the system clock anymore.
So I turned back to Windows’ built-in time synchronization. Indeed, the people at Meinberg also have helpful advice for it and suggest a few defaults to keep the system clock closely tied to an NTP reference clock. So here’s an attempt at configuring a clean NTP setup on Windows 10.
First of all, the timekeeping service needs to be stopped and fortunately Windows 10 provides the ability to start over with a fresh timekeeping configuration (all following actions must be applied using an administrator role):
net stop w32time w32tm /unregister w32tm /register
At this point, the defaults as suggested by Meinberg can be added to the registry:
Nachdem mein Macbook Pro auch schon wieder mehr als 4 Jahre auf dem Buckel hatte, musste ich langsam akzeptieren, dass das nächste kein Macbook mehr sein konnte. Ungelöste Mechanikprobleme an den aktuellen Tastaturen, fehlende Esc-Taste, und das ganze, da es ein dedizierter Grafikchipsatz sein sollte, ausschließlich zu abenteuerlichen Preisen um 3000 Euro. Da musste Apple leider mal draußen bleiben.
Nach qualvoller Evaluierung der Optionen entschied ich mich für das neue Dell Alienware m15 mit US-Tastatur, mattem 15.6″ Full-HD-Bildschirm mit 144Hz, Intel Core i7-8750H (6 Core, 12 Threads), 16 GB Arbeitsspeicher, Nvidia Geforce GTX 1060 und 3 Jahren Next-Day vor-Ort-Service. Die gewählte Konfiguration hat keine 2,5″-SATA-Festplatte mehr, sondern einen entsprechend von 60Wh auf 90Wh vergrößerten Akku.
Als Massenspeicher hatte ich das NVMe-Modul mit 256GB gewählt, das ich sofort nach Lieferung durch eines von Samsung mit 1TB getauscht habe. Bemerkenswert ist, dass noch ein zweiter NVMe-Slot frei ist, so dass man sich auch eine schicke und schnelle RAID-Konfiguration bauen könnte.
Das Gehäuse des m15 ist das flachste, das Alienware bisher angeboten hat. In Relation zum Display hat es aber einen auffallend großen Fußabdruck und hat ein 4:3-Format. Die sehr breiten schwarzen Ränder ober- und speziell unterhalb des Display habe ich zu Anfang als sehr störend empfunden. Ich nehme den ca. 5cm breiten unteren Rand aber aktuell als ergonomisch äußerst vorteilhaft wahr, da er das Display auf eine bessere Betrachtungsposition anhebt.
Tastatur und Verarbeitung gefallen mir sehr gut. Das Gehäuse sieht zwar sogar dort, wo es hochwertig aussehen soll, äußerst plastikhaft aus, ist aber tatsächlich aus Metall und gibt nirgends nach. Störend ist lediglich die geriffelte Fläche oberhalb der Tastatur, die Staub magisch anzieht. Um- und Aufrüstungen am m15 sind sehr einfach möglich, indem eine Handvoll Phillips-Schrauben rausgedreht werden und die untere Gehäusehälfte rundum mit einer einschlägigen Plastikkarte ausgeclipst wird. Danach liegen die NVMe- und RAM-Slots direkt frei. Hat man sich einmal an die sehr gute Tastatur des m15 gewöhnt und bekommt wieder eine Macbook-Tastatur unter die Finger, ist die Macbook-Tastatur mit ihrem widerwilligen Druckpunkt merklich schlechter.
Mit dem vorinstallierten Windows 10 hatte ich unglaublich viele Probleme vor allem im Bereich irgendwelcher Systemdateien, deren Ownership nicht stimmte. Das Diagnose-Tool von Samsung konnte nicht auf die SSD zugreifen, weil die NVMe-Slots im BIOS als “RAID” konfiguriert waren, was ich durchaus als unangenehme Schräglage empfand. Nach einer kompletten Windows-Neuinstallation macht das System keinerlei Probleme mehr und wirkt nicht mehr, als stamme es von einem besonders lieblos geklonten Image ab.
Erwartungsgemäß können die Lüfter des Notebook auch bei mäßigem Gebrauch immer mal wieder hörbar werden, etwa bei abenteuerlichen Workloads wie dem Betrachten eines Twitter-Feed mit einem eingebetteten animierten GIF. Die mitgelieferten Tools von Alienware sind erwartungsgemäß zu wenig zu gebrauchen, unter anderem auch nicht zum Heruntertakten des Prozessors. Mit dem einschlägig bekannten Tool ThrottleStop lässt sich der Takt aber soweit einschränken, dass das Gerät praktisch lautlos bleibt und man es bedenkenlos auf Knien oder Sofakissen benutzen kann. Wo man gerade dabei ist, erledigt man am besten auch die Belegung der Macro-Tasten über ein externes Tool. Mit Sharp Keys kann man sie etwa zu den Funktionstasten F13-F16 erklären, das ganze in die Registry schreiben (so dass Sharp Keys auch gleich wieder weg kann, vorzugsweise nachdem man auch CapsLock deaktiviert hat) und die neuen F-Tasten nach Geschmack mit Funktionen belegen. Ich schalte mit Macro 1 und Macro 2 zwischen dem mit ThrottleStop konfigurierten “Silent-/Batterie-Modus” und voller Leistung um.
Das Zusammenspiel zwischen CPU-Grafik und Nvidia-Grafik entpuppt sich dank irgendwelcher automatischer “Optimierungen”, die Alienware und der Nvidia-Treiber glauben vornehmen zu müssen, als größeres Gewurste, als erwartet. Läuft mein Spiel nun mit 60 FPS, weil irgendein Optimierungsquatsch das für ausreichend hält (wohlgemerkt auf einem 144Hz-Display, für das ich Aufpreis bezahlt habe), oder läuft es vielleicht auf der CPU statt auf dem Nvidia-Chipsatz? Diese Optimierungen sollen der Geräusch- und Wärmebegrenzung sowie der Verlängerung der Batterielaufzeit dienen, aber ernsthaft, wenn ich auf meinem 144Hz-Laptop ein Spiel starte, dann sitze ich mit Netzteil an der Steckdose, und sonst nirgends. Leider habe ich es aufgrund dieser Probleme noch nicht geschafft, Doom 2016 in einer Qualität laufen zu lassen, die an die Nvidia Geforce GTX 960 im einige Jahre alten stationären PC heranreicht. Counterstrike: Global Offensive geht dafür sehr gut. Immerhin.
Mit gedrosseltem Prozessor, auf 60Hz gedrosseltem Bildschirm (diese Drosselung muss man natürlich auch wieder mit einem externen Tool freischalten) und einfachen Workloads liegt die Batterielaufzeit oberhalb von 5 Stunden, womit sich auch längere Meetings problemlos bestreiten lassen.
Vom integrierten Ethernet-Port hatte ich mir einiges versprochen, aber die Warnungen, die mich diesbezüglich erreicht hatten, waren leider zutreffend und die Einbauposition sorgt bei besser verarbeiteten RJ45-Steckern wie dem Hirose TM31 dafür, dass diese sich von selbst entriegeln und das Kabel aus dem Port flutscht. Zuhause benutze ich also hauptsächlich einen USB-Ethernet-Adapter, den ich im Zweifelsfall zwecks Zugentlastung auf der jeweils anderen Gehäuseseite einstecken kann.
Der Umstieg vom Macbook zum Windows-Notebook war nicht wirklich schmerzhaft. Das einzige störende Element ist, dass man Windows immer in den Tiefschlaf schicken muss, da man bei Nutzung des normalen Ruhemodus wie unter MacOS praktisch täglich einen brüllend heißen Rechner aus der Tasche holt, der im zugeklappten Zustand aufgewacht ist.
Meine UNIX-Shell unter Windows habe ich per Cygwin abgebildet, und ansonsten sind die wichtigsten Tools (LibreOffice, Firefox, Thunderbird, GIMP) identisch mit denen, die ich auch unter MacOS oder Linux benutzen würde. Die “großen” kommerziellen Softwarepakete (in meinem Fall Adobe CC und DxO PhotoLab) sind heutzutage alle doppelt für MacOS und Windows lizensiert, so dass es hier zu keinen Überraschungen kam.
Da der Rechner nicht primär als Spiele-PC benutzt wird, hätte ich auf 144Hz zugunsten der besseren Farbtreue des 60Hz-Display verzichten oder sogar die Variante mit der höheren Auflösung wählen können. Davon abgesehen, bin ich mit dem Gerät sehr zufrieden und kann unter der Voraussetzung, dass nicht versucht wird, das vorinstallierte Windows zu benutzen, für das Alienware m15 eine klare Empfehlung aussprechen.
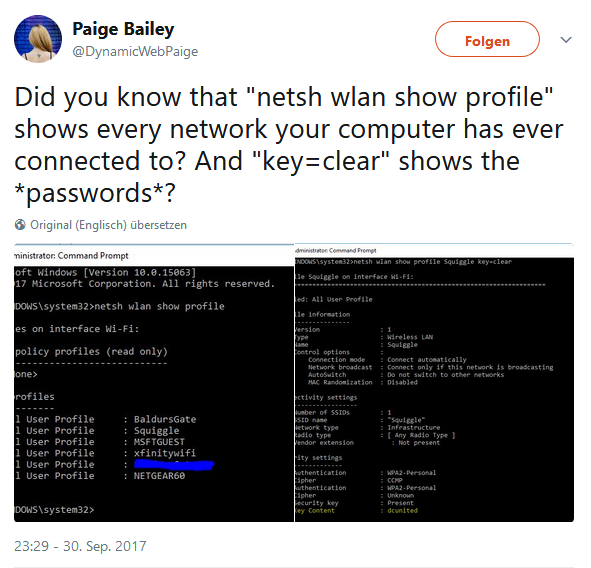
Did you know that “netsh wlan show profile” shows every network your computer has ever connected to? And “key=clear” shows the *passwords*?
No, I didn’t, and to be frank, I don’t care. But I recently played with NetworkManager on Linux and saw my Wifi passwords in discrete files under /etc/NetworkManager/system-connections/. So here’s how to show stored Wifi passwords on Windows, Linux and MacOS: Windows We’ve already seen that it’s quite straightforward, if you’re able to start a cmd shell as the system adminstrator. First, the list of used SSIDs:
netsh wlan show profile
Second, the password for any given SSID:
netsh wlan show profile <ssid> key=clear
Linux We can safely assume that anyone who configures their wpa-supplicant manually won’t be surprised that the passwords are stored in clear. So let’s move on to NetworkManager, which is what most Linux desktop users will use to connect to Wifi networks. NetworkManager stores one file each for every made network connection in the directory /etc/NetworkManager/system-connections/, so the simplest approach is to just grep for the passwords, in order to receive a comprehensive list:
macOS MacOS (whatever way it’s supposed to be capitalized this time around) makes the task quite hard, because the saved networks are stored in a property list and the passwords need to be retrieved from the key ring one by one. Here’s how to list the SSIDs of the saved networks:
Everybody knows that one of these is a random IP address according to RFC 4941: Privacy Extensions for Stateless Address Autoconfiguration in IPv6 that changes once in a while so external observers (e.g. accessed web servers) can’t keep track of my hardware’s ethernet MAC address. This is the one we do NOT want if we want to access the Macbook from the internet. We want the stable one, the one that has the MAC address encoded within, the one with the ff:fe in the middle, as we all learned in IPv6 101. It turns out, all of my devices that configure themselves via SLAAC, namely a Macbook, an iPhone, an iPad, a Linux laptop and a Windows 10 workstation, don’t have ff:fe addresses. Damn, I have SAGE status at he.net, I must figure out what’s going on here! After a bit of research totally from scratch with the most adventurous search terms, it turns out that these ff:fe, or more professionally, EUI-64 addresses, have become a lot less common than 90% of IPv6 how-to documents and privacy sceptics want us to believe. On most platforms, they have been replaced by Cryptographically Generated Addresses (CGAs), as described in RFC 3972. The RFC is a close relative to RFC 3971, which describes a Secure Neighbor Discovery Protocol (SeND). Together, they describe a cryptographically secure, PKI-based method of IPv6 address generation. However, as of this writing, only a PKI-less stub implementation of RFC 3972 seems to have become commonplace. Those CGAs, or as some platforms seem to call them, Privacy Stable Addresses, are generated once during the first startup of the system. The address itself, or the seed used to randomize it, may be (and usually is) persistently stored on the system, so the system will come up every time with this same IPv6 address instead of one following the well-known ff:fe pattern. To stick with the excerpt from my macOS ifconfig output above, the address marked temporary is a Privacy Extension address (RFC 4941), while the one marked secure is the CGA (RFC 3972). It’s surprisingly hard to come up with discussions on the web where those two types aren’t constantly confused, used synonymously, or treated like ones that both need to be exterminated, no matter the cost. This mailing list thread actually is one of the most useful resources on them. This blog post is a decent analysis on the behaviour on macOS, although it’s advised to ignore the comments. This one about the situation on Windows suffers from a bit of confusion, but is where I found a few helpful Windows commands. The nicest resource about the situation on Linux is this german Ubuntuwiki entry, which, given a bit of creativity, may provide a few hints also to non-german speakers. So, how to configure this?
macOS
The related sysctl is net.inet6.send.opmode.
Default is 1 (on).
Note how this is the only one that refers to SeND in its name.
Windows
netsh interface ipv6 set global randomizeidentifiers=enabled store=persistent
netsh interface ipv6 set global randomizeidentifiers=disabled store=persistent
Default seems to be enabled.
Use store=active and marvel at how Windows instantly(!) replaces the address.
Linux
It’s complicated.
NetworkManager defaults to using addr-gen-mode=stable-privacy in the [ipv6] section of /etc/NetworkManager/system-connections/<Connection>.
The kernel itself generates a CGA if addrgenmode for the interface is set to none and /proc/sys/net/ipv6/conf/<interface>/stable_secret gets written to.
NetworkManager and/or systemd-networkd take care of this. I have no actual idea.
In manual configuration, CGA can be configured by using ip link set addrgenmode none dev <interface> and writing the stable_secret in a pre-up action. (See the Ubuntu page linked above for an example.)
FreeBSD
FreeBSD has no support for CGAs, other than a user-space implementation through the package “send”, which I had no success configuring.
So far, I haven’t been able to tell where macOS, Windows and NetworkManager persistently store their seeds for CGA generation. But the next time someone goes looking for an ff:fe address, I’ll know why it can’t be found.
So I was looking at yet another failed apt-get upgrade because /boot was full. After my initial whining on Twitter, I immediately received a hint towards /etc/apt/apt.conf.d/01autoremove-kernels, which gets generated from /etc/kernel/postinst.d/apt-auto-removal after the installation of new kernel images. The file contains a list of kernels that the package manager considers vital at this time. In theory, all kernels not covered by this list should be able to be autoremoved by running apt-get autoremove. However it turns out that apt-get autoremove would not remove any kernels at all, at least not on this system. After a bit of peeking around on Stackexchange, it turns out that this still somewhat newish concept seems to be ridden by a few bugs, especially concerning kernels that are (Wrongfully? Rightfully? I just don’t know.) marked as manually-installed in the APT database: “Why doesn’t apt-get autoremove remove my old kernels?” The solution, as suggested by an answer to the linked question, is to mark all kernel packages as autoinstalled before running apt-get autoremove:
I’m not an APT expert, but I’m posting this because the post-install hook that prevents the current kernel from being autoremoved makes the procedure appear “safe enough”. As always, reader discretion is advised. And there’s also the hope that it will get sorted out fully in the future.
What goes up, must come down. Ask any system administrator.